LDA Topic Modeling
By Megan Kane
Full Code Available on SF Nexus Github:
LDA (Gensim) Topic Modeling is based on the assumption that documents are a mixture of topics (# topics is set by the researcher) and that topics are a mixture of words. To determine which words belong to each topic, the LDA model randomly assigns each word in a set of documents to a topic, then iterates through the assignments and makes adjustments until all words are assigned to the topics where they have the highest probability of belonging. LDA topic modeling works well on disaggregated texts (like the dataset generated above).
We ran topic modeling on a subset of Temple’s science fiction corpus which has been identified as “climate fiction.” Using C_V and U_Mass Coherence calculations, we determined that optimal number of topics for the sci-fi collection was 200. In other words, a model with 200 topics provides the most coherent co-occurences of words and documents in each topic. Prior to this analysis, all stopwords and non-English words were removed. Here are the most frequent words present in the top topics in the model.
Sample interactive visualization of LDA topic models of climate fiction using LDAviz
BERTopic Topic Modeling
Full Code Available on SF Nexus Github:
BERTopic Topic Modeling is a topic modeling tool which creates topic clusters based on word embeddings and a class-based TF-IDF. It generates a set of topics, the top words in each topic, and the likelihood of each text in a corpus belonging to each topic. Because it makes use of word embeddings, it does not work well with disaggregated texts.
Unlike LDA, BERTopic automatically chooses the number of topics to generate within the model, though parameters can be set to collapse extremely similar topics. Performing BERTopic modeling on the sci-fi corpus yielded 91 topics, excluding Outliers.
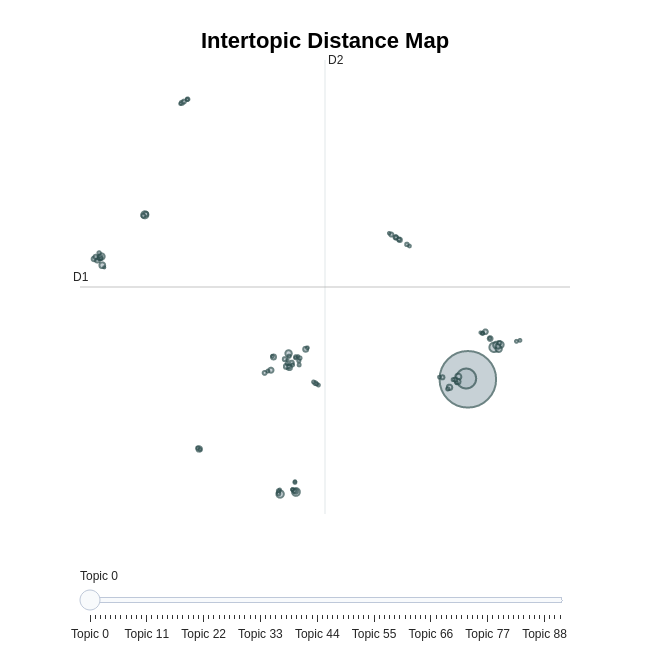
Here is a 2d representation of the topics in our BERTopic model:
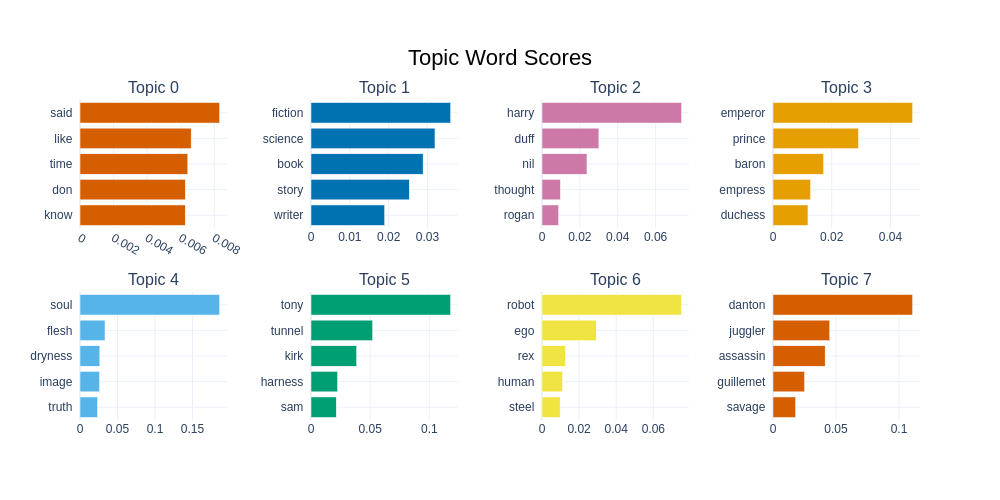
To get a closer look at the topics, we can extract and visualize the top words per topic. Here is a bar chart visualization of the top words appearing in the top 8 topics occurring in the corpus:
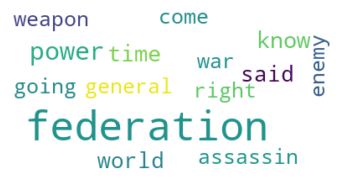
Here are the most frequent words in some specific topics of interest:
Topic 33: War Command
Topic 18: Disease Outbreak

Topic 47: Energy

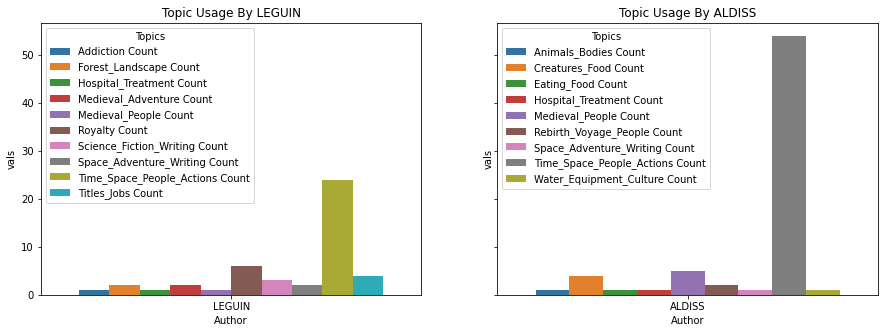
Topic Usage Comparison Between Authors
We can also explore usage of topic per author. Here, for example, is a distribution of the topics used By Brian Aldiss vs. Ursula Le Guin:
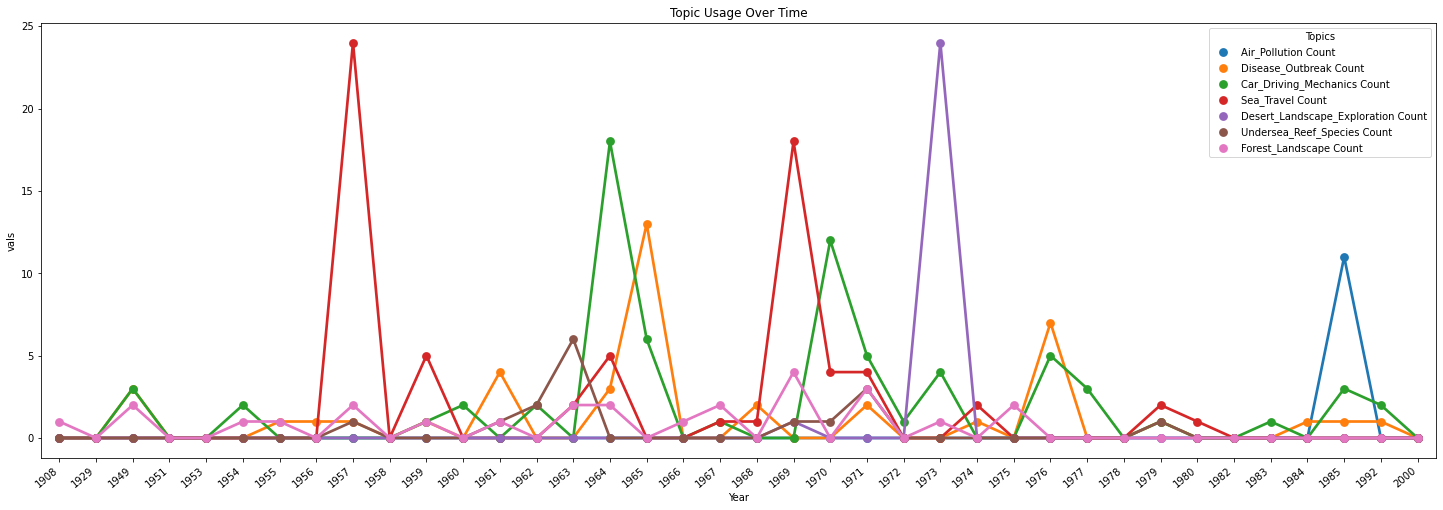
Topic Usage Over Time
This graph shows the frequency with which authors use topics of interest throughout the 20th century. Note: frequency is calculated each time a “chapter/chunk” from a book uses the topic most frequently, so the most frequently used topics might be frequent because of their prevalence across chapters of a particular book rather than across multiple books. This is something to fine-tune in how we build the visualization.
Mapping Semantic Similarity with Atlas
Full Code Available on SF Nexus Github:
Atlas is a web platform for exploring large datasets. Researchers can use Atlas to cluster texts based on semantic similarity and project them onto a map, as below. From here, similarities between data points can be investigated, datasets can be refined, and new maps can be build based on relevant subset of data. Maps served on the Atlas browser, Nomic, can be set for public sharing and interaction.
We used Python to map embeddings of a subset of our science fiction corpus - 142 texts specifically identified as “climate fiction.” Along with these texts, we mapped embeddings of Science Fiction, Detective Fiction and Fantasy texts from Project Gutenberg. This allowed us to explore the semantic similarities between the three major genres (science fiction, detective fiction and fantasy) as well as any distinctions between climate fiction texts and the broader genre of science fiction.
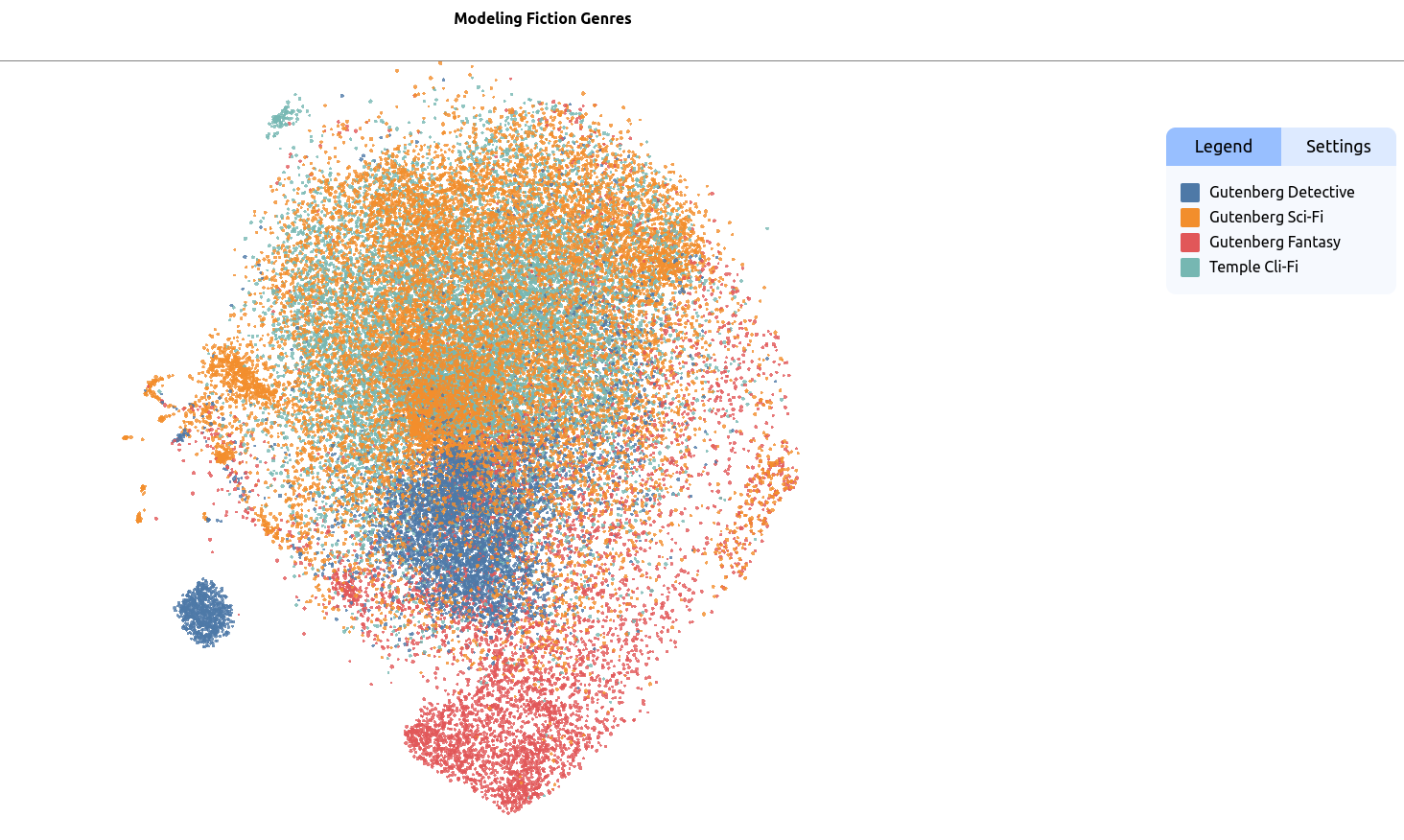
View an interactive version of this map on the Nomic Atlas website.