Our core SF corpus is comprised of 403 texts from the Temple University SCRC Paskow Science Fiction Collection. The corpus primarily contains New Wave SF novels published between 1945 and 1990, along with short story anthologies and magazines. The texts have been scanned, digitized and saved as .txt files using ABBYY Finereader for Optical Character Recognition (OCR). After making the texts machine readable and post-processing and cleaning the OCR’ed text, we have curated several datasets of varying granularity available at this time.
Because the majority of texts in our corpus are under copyright, sharing the original, full-text works is a violation of copyright law. However, it is permissible to share “extracted features” from these works, such as disaggregated texts, word frequency counts, and syntactical and semantic descriptors. Extracted features can be used for a variety of analyses, including topic modeling. The following extracted features datasets are currently available for public use:
- EF_Full_Texts: A dataframe containing disaggregated (“bag of words”) versions of all 403 texts
- EF_Chapters_and_Chunks: A dataframe containing disaggregated (“bag of words”) versions of all 403 texts, with each text split into chapters and “chunks” of approximately 1000 words
- EF_Chapters_Only: A dataframe containing disaggregated (“bag of words”) versions of the 306 texts in our corpus which contain chapters, as split into chapters.
Each dataframe contains two versions of the text: one that has been “cleaned” through lowercasing and removal of punctuation, extra spaces and numbers, and one that has not been cleaned. The dataframes also contain some basic metadata about the books at hand, including title, author name, publication year, and word count. The metadata curation process is ongoing to include more information about publication, description and genre categorization from the Library of Congress.
If you upload one of the dataframes into Python for analysis, its head should look like this:

Two additional extracted features datasets have been generated using BookNLP:
- EF_Named_Entities: CSV files containing information about the “named entities” appearing in the 403 texts: people, organizations, locations, vehicles, among others.
- EF_Supersense_Tags: CSV files containing information about a broader collection of entities appearing in the 403 texts - not only people, places, and locations, but also tokens identified as “emotions,” “substances,” or “artifacts,” among others.
All of our extracted features sets can be accessed through our SF Nexus HuggingFace repository. HuggingFace datasets can be downloaded from repositories as in Github; they can also be called directly in Python, where they will be downloaded to your local computer and split into training and testing groups in preparation for analysis. Use this code to download the SF_Extracted_Features_Chapters_and_Chunks dataset:
# Import dataset module
from datasets import load_dataset
# Load the corpus of texts saved to the SF Nexus repository
dataset = load_dataset("SF-Corpus/EF_Chapters_and_Chunks")
For more information about working with HuggingFace datasets, review their reference guide
An extended discussion on extracted features can be found on the Scholars’ Studio blog, in Jeff Antsen’s “Curating Copyrighted Corpora: AN R Script for Extracting and Structuring Textual Features”.
This project made use of multiple Python and R pipelines to extract features from the science fiction collection. These pipelines are available as both Jupyter Notebooks and Google Colab Notebooks in this Github repository. Below, the process for crafting each extracted features dataset is discussed in more detail.
Pipeline 1: Text Sectioning and Disaggregation
Full Code Available on SF Nexus Github:
- Text_Sectioning and Disaggregation.ipynb (Google Colab)
- Text_Sectioning and Disaggregation.ipynb (Jupyter Notebook)
- Text_Sectioning and Disaggregation.R (R)
Our first pipeline focuses on sectioning and disaggregating the science fiction texts. Breaking texts into sections (in this case, chapters and n-word chunks) is helpful for researchers working with large texts and corpora. In our case, many of the science fiction texts in the sci-fi collection are 50,000+ words long - quite a lot of words per text to process! Sectioning the data into chapters and “chunks” of 1000 words or less enables faster processing time when analyses like topic modeling and word2vec are performed. It also allows researchers to ask more granular questions about the composition of their texts; for example, what multiple topics or themes emerge across chapters of a book, and what do these indicate about the text’s narrative arc?
Disaggregation is the process of transforming full texts into “bag-of-word” models that are not human-readable. These bag-of-word models can be shared where copyrighted full texts cannot, and they’re still usable in processes like LDA topic modeling which rely primarily on word frequencies rather than word order.
Input: Machine-readable versions (TXT files) of 403 science fiction books
To develop an extracted features dataset of the full corpus, we first split each text into segments of 1000 words each. These text “chunks” may be particularly useful for analyses like topic modeling given their uniformity across texts, whereas other ways of segmenting texts (like per chapter, as below) will yield segments of various lengths. Here is how the process works in Python (documentation of the R pipeline available on our Github repository).
# Define chunking function
def split(list_a, chunk_size):
for i in range(0, len(list_a), chunk_size):
yield list_a[i:i + chunk_size]
# Set desired size of chunks
chunk_size = 1000
# Create new list for chunked sentences
chunked_ch = []
# Perform chunking function on each row of tokens
s = new_chapters_df['Tokens']
for content in s:
chunks = list(split(content, chunk_size))
# Add to new list
chunked_ch.append(chunks)
After running the segmentation function, we sorted the words in each segment alphabetically in order to transform them from human-readable texts to “bags of words.” The resulting extracted feature set of disaggregated, chapterized texts is available for download on our SF Nexus Hugging Face repository.
Output 1: Disaggregated Versions of 403 Texts, Split into 1000-Word Segments.
We also developed another set of extracted features from our corpus: disaggregated texts split by chapter, rather than 1000-word chunk. Chapter segmentation was possible for a large subsection of our corpus (306 texts), given standardized chapter naming conventions employed during the OCR cleaning process. Python code was written to retrieve all text between the “START OF BOOK” and “END OF BOOK” tags in each text, excluding info on title pages, dedications, acknowledgements, etc. From here, we searched for each instance of “CHAPTER” in each text and split the text whenever an occurence was found.
# Count number of chapters in each text
chapter_counts = books_cleaned['Text'].str.count('CHAPTER')
# Append chapter counts to dataframe
books_cleaned["Chapters"] = chapter_counts
# Make new cell each time new chapter starts
new = books_cleaned["Text"].str.split("CHAPTER", expand = True).set_index(books_cleaned['Title'])
The resulting DataFrame contained each chapter of each book as a separate text.

After splitting texts by chapters, we again sorted the words in each chapters alphabetically in order to transform them from human-readable texts to “bags of words.”
Output 2: Disaggregated Versions of 306 Texts, Split into Chapters.
Finally, we disaggregated the full versions of each text files, for use for researchers who are not interested in using smaller chunks (chapters or 1000-word segments) in their analyses.
Output 3: Disaggregated Versions of 403 Full Texts.
Pipeline 2: Part-of-Speech Tagging, Named Entity Recognition, and Supersense Tagging
Full Code Available on SF Nexus Github:
Our second pipeline focuses on “enriching” the SF corpus by extracting information like parts of speech, named entities, and “supersense tags” (e.g., “animal”, “artifact”, “body”, “cognition”, etc.) from each text. This information (and much more) can be retrieved by running BookNLP in Python. Developed by David Bamman at UC Berkeley, BookNLP is a natural language processing pipeline for large texts. Its functionalities include:
- tokenization
- sentence boundary identification
- part of speech tagging
- dependency parsing
- entity recognition
- entity mapping (aligning aliases to a single character ID)
- gender prediction Digital humanists have used BookNLP in a variety of capacities, including analyses of character and gender bias in children’s literature. For a more comprehensive introduction to BookNLP, check out Introduction to BookNLP by W.J.B. Mattingly.
Input: Machine-readable versions (TXT files) of 403 science fiction books
We ran the aggregated full texts in our SF collection through BookNLP in Python. Only a few lines of code are needed to run BookNLP in Python:
# Define folder where files are stored to run BookNLP on
files = [f for f in os.listdir(path) if os.path.isfile(f)]
# Loop to run book NLP on each file
for f in files:
# Define filename as each file in folder
inputFile = f
# Set folder for booknlp results
outputDir = "BookNLP_Results/"
# Set ID as name of each file
idd = f
# Run book nlp on each file
booknlp.process(inputFile, outputDir, idd)
The result of the code above is a folder containing several BookNLP-generated files for each text. Two types of files are available to access on our SF Nexus Github page.
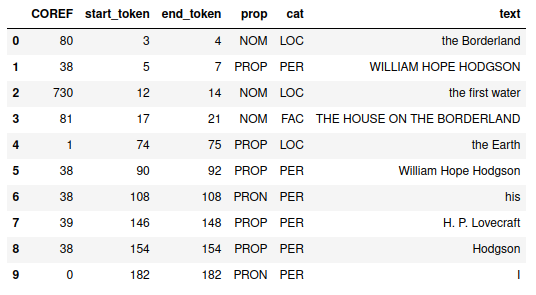
Output 1: Entities files for 403 science fiction books
- Files containing information about the “named entities” appearing in the texts: people, organizations, locations, vehicles, among others. As seen in the output, the entity file also denotes the part of speech of each entity and their position in the text.
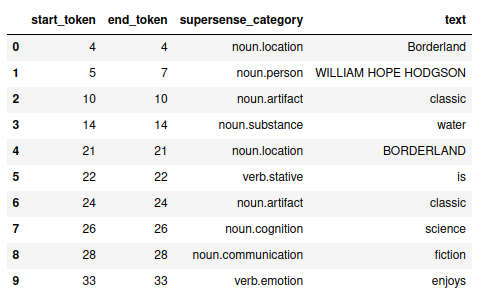
Output 2: Supersense files for 403 science fiction books
- Files containing information about a broader collection of entities appearing in the texts - not only people, places, and locations, but also tokens identified as “emotions,” “substances,” or “artifacts,” among others. As seen in the output, the supersense file also denotes the part of speech of each entity and their position in the text.
For a more comprehensive overview of BookNLP’s output, check out Chapter 3: “The Output Files” in W. J. B. Mattingly’s Introduction to BookNLP.
Take Down Notice
This site only exhibits extracted features for copyrighted fiction; no copyrighted work is being made available for consumption. These digitized files are made accessible for purposes of education and research. Temple University Libraries have given attribution to rights holders when possible. If you hold the rights to materials in our digitized collections that are unattributed, please let us know so that we may maintain accurate information about these materials.
If you are a rights holder and are concerned that you have found material on this website for which you have not granted permission (or is not covered by a copyright exception under US copyright laws), you may request the removal of the material from our site by writing to digitalscholarship@temple.edu. For more information on non-consumptive research, check out HathiTrust Research Center’s Non-Consumptive Use Research Policy.
Full Text Analysis within the HathiTrust Research Center Data Capsule
Researchers can remotely access the full texts in a controlled manner for full-text access and analysis through the HathiTrust Research Center Data Capsule. Learn more about the HathiTrust Data Capsule here and visit this Github repository to set up and run a data capsule appliance.